
Understanding DevOps vs MLOps has become critical for technology leaders as AI adoption accelerates across industries. While DevOps vs MLOps share fundamental principles like automation and continuous delivery, they address distinctly different operational challenges in software development and machine learning lifecycles. With the MLOps market projected to reach $16.61 billion by 2030 at a CAGR of 40.5%, distinguishing these methodologies is no longer just technical—it’s strategic.
This comprehensive guide explores the essential differences, similarities, tools, workflows, and best practices for both DevOps and MLOps, helping organizations determine when to implement each approach for maximum operational efficiency and business value.
What is DevOps?
DevOps combines Development (Dev) and Operations (Ops) into a unified methodology that integrates the software development lifecycle. It shortens the development process through automation, continuous delivery, and feedback loops, transforming traditional siloed processes into agile, successive phases.
Core DevOps Principles:
Continuous Integration (CI): Developers merge code changes into a shared repository multiple times daily, with automated builds and tests running on each commit to identify conflicts early.
Continuous Delivery/Deployment (CD): Automated release processes deliver tested code to staging or production environments, minimizing manual intervention and reducing time between development and deployment.
Infrastructure as Code (IaC): Infrastructure is defined through code using tools like Terraform, enabling version control, repeatability, and consistent environment provisioning.
Monitoring and Feedback: Continuous monitoring of application performance, uptime, and system health drives ongoing improvements and rapid issue resolution.

What is MLOps?
MLOps (Machine Learning Operations) extends DevOps principles specifically for machine learning model development, deployment, and maintenance. It bridges the gap between data science experimentation and production-ready ML systems, addressing unique challenges like data drift, model versioning, and continuous training.
Core MLOps Principles:
Data-Centric Operations: MLOps manages dynamic datasets, feature engineering, and data pipelines alongside code, requiring versioning for data, models, and experiments.
Continuous Training (CT): Beyond CI/CD, MLOps includes continuous training to retrain models automatically as new data becomes available or performance degrades.
Model Monitoring: Real-time tracking of model performance metrics, data drift, concept drift, and prediction accuracy ensures models remain effective in production.
Experiment Tracking: Systematic logging of hyperparameters, model versions, training data, and performance metrics enables reproducibility and comparison across experiments.
DevOps vs MLOps: Key Differences
While both methodologies share automation and collaboration principles, their operational focus differs significantly.
Primary Focus
DevOps centers on software application development, testing, and deployment, managing static code artifacts and traditional software delivery pipelines. MLOps prioritizes machine learning model lifecycle management, handling dynamic datasets, model training, and inference services.
Data Handling
DevOps works with static software artifacts including source code, binaries, and configuration files that remain consistent once built. MLOps manages ML-specific artifacts like datasets, trained models, features, and experiment configurations that evolve continuously through retraining and data changes.
Development Artifacts
In DevOps, code generates executable artifacts that create application interfaces after testing and validation. In MLOps, code produces serialized model files that accept data inputs and generate predictions, requiring validation against test datasets rather than functional testing.
Version Control Requirements
DevOps tracks code changes and deployment artifacts through standard version control systems like Git. MLOps requires comprehensive versioning of code, data, models, hyperparameters, and experiment metadata to ensure reproducibility and model lineage tracking.
Testing Approaches
DevOps employs unit tests, integration tests, and end-to-end tests focusing on code functionality and system behavior. MLOps includes data validation, model quality validation, model performance testing, and statistical testing to verify prediction accuracy.
Deployment Complexity
DevOps follows predictable CI/CD patterns with deterministic deployment outcomes. MLOps deployment includes Continuous Training (CT) alongside CI/CD, accounting for model retraining triggers, data drift detection, and A/B testing of model versions.
Monitoring Requirements
DevOps monitors application health metrics like CPU usage, memory, latency, and error rates. MLOps extends monitoring to include model-specific metrics such as prediction accuracy, precision, recall, F1-score, data drift, and concept drift.
Infrastructure Needs
DevOps utilizes standard computing resources and containerization platforms. MLOps demands specialized hardware including GPUs for training, distributed computing infrastructure, and optimized inference servers for model serving.
Team Composition
DevOps teams consist of software engineers, DevOps engineers, and QA specialists. MLOps teams expand to include data scientists, ML engineers, data engineers, DevOps engineers, and business analysts.

Essential DevOps Tools and Technologies
Version Control and Collaboration
Git, GitHub, GitLab, and Bitbucket provide distributed version control, enabling code tracking, branching strategies, and team collaboration.
CI/CD Automation
Jenkins: Open-source automation server with 1,000+ plugins for building, testing, and deploying applications across the development lifecycle.
GitLab CI/CD: Integrated CI/CD within GitLab repositories with Auto DevOps features and Kubernetes support.
CircleCI: Cloud-native CI/CD platform with rapid setup, parallel test execution, and automatic scaling for large workloads.
Travis CI: Popular for open-source projects with straightforward configuration and GitHub integration.
Containerization and Orchestration
Docker: Industry-standard containerization platform creating lightweight, portable application environments with minimal overhead.
Kubernetes: Enterprise-grade container orchestration system managing deployment, scaling, load balancing, and self-healing across distributed systems.
Infrastructure as Code
Terraform: Provider-agnostic IaC tool using declarative HashiCorp Configuration Language (HCL) to provision and manage multi-cloud infrastructure.
Ansible, Chef, Puppet: Configuration management tools automating infrastructure provisioning and application deployment.
Monitoring and Observability
Prometheus: Open-source time-series database and monitoring system with powerful PromQL query language for metrics collection and alerting.
Grafana: Visualization platform transforming Prometheus metrics into customizable dashboards with real-time monitoring capabilities.
Datadog: Comprehensive cloud-scale monitoring platform for infrastructure, applications, and logs with AI-powered insights.
ELK Stack (Elasticsearch, Logstash, Kibana): Centralized logging and analysis solution for troubleshooting and performance optimization.
Essential MLOps Tools and Platforms
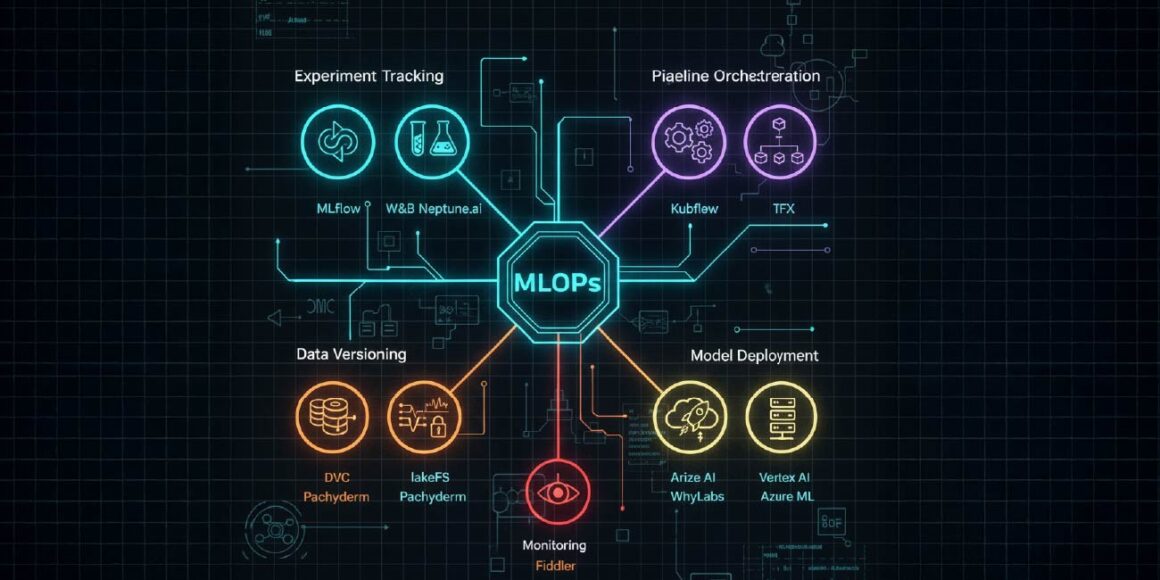
Experiment Tracking and Model Registry
MLflow: Open-source framework providing experiment tracking, model registry, project packaging, and model deployment with support for major ML libraries.
Weights & Biases (W&B): Leading platform for experiment tracking, real-time visualization, hyperparameter tuning, and team collaboration.
Neptune.ai: Metadata store for ML experiments enabling comparison, versioning, and reproducibility across projects.
Pipeline Orchestration
Kubeflow: Kubernetes-native end-to-end ML platform orchestrating portable, scalable workflows with integrated notebooks, training operators, and KServe for model serving.
Apache Airflow: Workflow orchestration tool automating data preprocessing, model training, and deployment pipelines.
TensorFlow Extended (TFX): Production-ready ML platform for deploying TensorFlow models with end-to-end pipeline components.
Data and Pipeline Versioning
DVC (Data Version Control): Git-like versioning for datasets, models, and ML pipelines enabling reproducibility and collaboration.
lakeFS: Open-source data versioning system providing Git operations (branching, committing, merging) for object storage and data lakes.
Pachyderm: Data versioning and pipeline automation on Kubernetes supporting any data type, language, and scale.
Model Deployment and Serving
AWS SageMaker: Fully managed service for building, training, and deploying ML models with integrated MLOps capabilities.
Azure Machine Learning: Enterprise ML platform with automated ML, model management, and deployment across cloud and edge.
Google Vertex AI: Unified AI platform combining AutoML and custom training with streamlined model deployment.
TensorFlow Serving: High-performance serving system for TensorFlow models in production environments.
Model Monitoring and Drift Detection
Arize AI: ML observability platform for real-time performance tracking, drift detection, and automated monitoring with PagerDuty and Slack integrations.
WhyLabs: Model monitoring tool detecting data quality degradation, data drift, and bias using privacy-preserving whylogs library.
Fiddler: User-friendly monitoring platform for performance tracking, data integrity checks, outlier detection, and model explainability.
Datadog ML Monitoring: Comprehensive monitoring for model accuracy, precision, recall, infrastructure health, and GPU utilization.

DevOps Workflow and Best Practices
Establish Collaborative Culture
Break down silos between development, operations, and QA teams through shared ownership, transparent communication, and blameless post-mortems that treat failures as learning opportunities.
Implement Comprehensive CI/CD Pipelines
Automate the entire software delivery process from code commit through production deployment, including automated testing, security scanning, and deployment validation.
Code Commit and Version Control: Track all changes in Git with descriptive commit messages and effective branching strategies like GitFlow.
Automated Build: Compile source code, resolve dependencies, and create deployable artifacts automatically on each commit.
Automated Testing: Execute unit tests, integration tests, and end-to-end tests to catch bugs early and ensure code quality.
Staging Deployment: Deploy validated builds to staging environments simulating production for final validation.
Production Deployment: Implement deployment strategies like blue-green deployments, canary releases, or rolling updates to minimize downtime.
Adopt Infrastructure as Code
Define all infrastructure through version-controlled code using Terraform, CloudFormation, or similar tools, ensuring consistent, reproducible environments across development, staging, and production.
Embrace Microservices Architecture
Break applications into small, independent services that can be developed, tested, deployed, and scaled independently, promoting fault isolation and rapid innovation.
Implement Continuous Monitoring
Deploy comprehensive monitoring using Prometheus and Grafana to track system health, application performance, resource utilization, and user experience metrics in real-time.
Automate Repetitive Tasks
Identify and automate manual processes including testing, deployment, infrastructure provisioning, and configuration management to reduce errors and accelerate delivery.
Practice Continuous Feedback
Engage users, stakeholders, and team members regularly to gather feedback that shapes release cycles and ensures development aligns with business objectives.
Prioritize Security and Compliance
Integrate security practices throughout the development lifecycle (DevSecOps) with automated security scanning, access controls, encryption, and compliance monitoring.
MLOps Workflow and Best Practices
Data Ingestion and Validation
Collect data from diverse sources (databases, APIs, IoT devices) and implement automated validation checks for completeness, accuracy, and consistency before model training.
Feature Engineering and Management
Create, transform, and store features in centralized feature stores enabling reuse across projects and maintaining consistency between training and inference.
Model Training and Experiment Tracking
Systematically log hyperparameters, training data versions, model architectures, and performance metrics using MLflow or W&B to ensure reproducibility and enable comparison.
Implement Continuous Integration for ML
Automate testing of data schemas, feature generation, model training code, and model validation, building packages and executables for deployment pipelines.
Deploy Continuous Training Pipelines
Establish automated model retraining triggered by performance degradation, data drift detection, or scheduled intervals to keep models current with evolving data patterns.
Data Extraction: Collect only necessary data from source systems.
Data Validation: Verify data presence, format, and quality.
Data Preparation: Process and transform data for model training.
Model Training: Train models using processed data and optimized hyperparameters.
Model Evaluation: Assess model performance against validation datasets.
Model Validation: Compare new model performance with existing production models through A/B testing.
Establish Model Registry
Maintain centralized model registries tracking all model versions, associated metadata, performance metrics, and lifecycle stages (development, staging, production).
Deploy Comprehensive Model Monitoring
Implement real-time monitoring for prediction accuracy, data drift, concept drift, feature distribution changes, and infrastructure performance using specialized MLOps monitoring tools.
Data Drift: Changes in input data distribution compared to training data.
Concept Drift: Changes in the relationship between inputs and outputs over time.
Model Drift: Degradation in model performance due to data or concept drift.
Automate End-to-End Workflows
Build fully automated ML pipelines encompassing data ingestion, preprocessing, training, validation, deployment, and monitoring to accelerate experimentation and deployment cycles.
Ensure Model Governance and Compliance
Implement robust governance mechanisms for transparency, data management, model explainability, and human oversight to meet regulatory requirements like the EU AI Act.
Foster Cross-Functional Collaboration
Create integrated teams combining data scientists, ML engineers, DevOps specialists, and business stakeholders with shared documentation, integrated dashboards, and clear ownership models.
Prioritize Reproducibility
Version control all artifacts including code, data, models, environment configurations, and dependency specifications to ensure experiments and deployments can be reliably reproduced.

When to Use DevOps vs MLOps
Choose DevOps When:
Your primary focus is traditional software application development, web services, APIs, or microservices without machine learning components. The project involves standard application logic with predictable behavior and deterministic outputs. Development cycles prioritize feature delivery, bug fixes, and infrastructure management. Team composition centers on software engineers and operations specialists without data science requirements.
Choose MLOps When:
Projects involve developing, deploying, and maintaining machine learning models requiring continuous retraining and performance monitoring. Data is central to operations, with models dependent on evolving datasets and requiring drift detection. Organization needs experiment tracking, model versioning, and reproducibility across ML workflows. Teams include data scientists and ML engineers requiring specialized tools for model lifecycle management. Business value depends on model accuracy, prediction quality, and adaptation to changing patterns.
Implement Both When:
Building AI-powered applications requiring both traditional software development and machine learning capabilities. Organizations need unified infrastructure supporting standard applications and specialized ML workloads. Teams must collaborate across software engineering, data science, and operations disciplines. Projects demand end-to-end automation from data pipelines through model deployment and application delivery.

Future Convergence: AIOps and Unified Operations
The boundaries between DevOps and MLOps continue to blur as organizations adopt unified operational practices. By 2030, MLOps will achieve mainstream adoption comparable to current DevOps practices, with automated machine learning lifecycles becoming standard across industries.
AIOps emerges as a convergent approach using AI to streamline IT infrastructure management while MLOps and DevOps concentrate on their respective domains. Rather than separate disciplines, these practices increasingly function as parallel areas with shared tools, workflows, and integrated pipelines.
Organizations successfully implementing both practices report 3-15% profit increases through enhanced innovation velocity, cost optimization, and strategic alignment across departments. The key to competitive advantage lies not in choosing one methodology over the other, but in understanding when and how to apply each approach effectively while fostering collaboration across disciplines.
Edge computing and real-time MLOps for IoT devices, compliance-driven governance for AI regulation, and automated ML lifecycle management will define the next evolution of operations practices, making the distinction between DevOps and MLOps less about separation and more about specialized expertise within unified operational frameworks.
Don’t stop here—discover more in our latest blog –
Why n8n Automation Is the Future for Growing Businesses
Cloud ERP vs On-Premise ERP: Which One Is Better for Automation?
API-First Development: The Blueprint for Modern Software Architecture
Payment Gateway Failures: How to Stop Losing 42% of Failed Payment Customers
Post Views: 419



